Digging Into Kafka: Key Concepts, Architecture, Benefits, and Use Cases for Backend and Full Stack Developers

What is Kafka?
Kafka is an event streaming platform designed for real-time data processing. It enables systems to publish and subscribe to events while offering fault tolerance, scalability, and low-latency data pipelines.
Here’s how Kafka works:
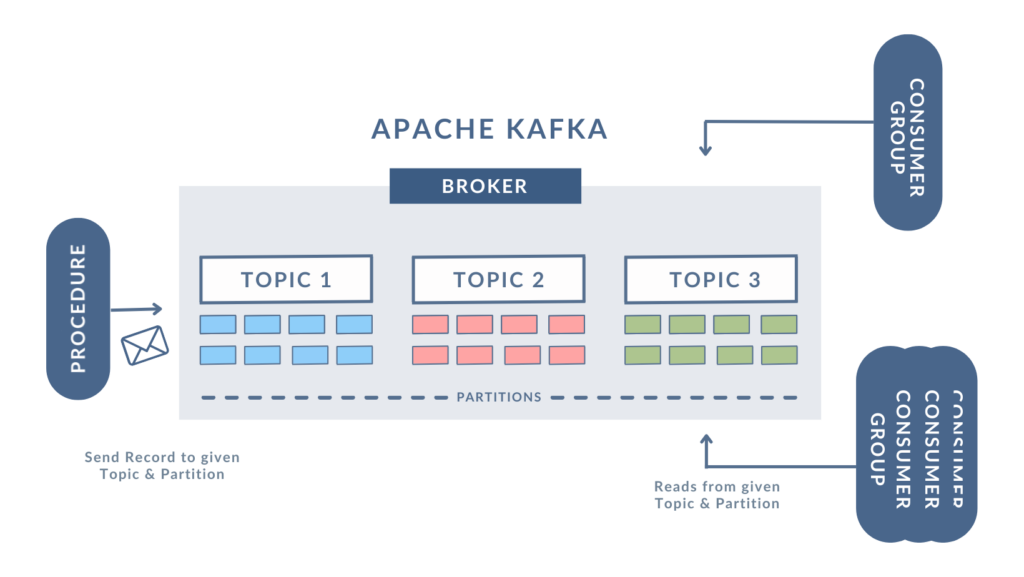
- Topics: Events are stored in order; immutable logs called topics. Kafka stores data by distributing and replicating it across several servers, referred to as brokers, to ensure reliability and fault tolerance.
- Producers: Producers send records (events) to topics whenever an event occurs.
- Consumers: Consumers subscribe to topics and read records in real time or at their convenience.
- Durability: Events are stored on disk and can be retained for long durations based on configured policies.
Kafka’s design is a game-changer for extended development teams, allowing seamless integration of backend and full-stack solutions.
Kafka’s Core Architecture
- Event:
- A record of an occurrence (e.g., “Room temperature is increasing to 34°C”).
- Contains three parts:
- Key: Identifies the event (e.g., “Room Temperature”).
- Value: Event details (e.g., “Temperature at 34°C”).
- Timestamp: When it happened (e.g., “Aug. 18, 2018, 2:06 PM”).
- Topic:
- The central log where events are stored in order.
- Supports multiple producers writing events and multiple consumers subscribing to them simultaneously.
- Producers and Consumers:
- Producers publish events to topics without needing to know if consumers are available.
- Consumers fetch events from topics, ensuring decoupled communication.
Key Benefits of Kafka
Kafka is ideal for software development projects requiring speed, reliability, and scalability:
- Scalability: Easily handles large data loads by scaling horizontally.
- Low Latency: Real-time processing ensures minimal delays.
- Data Persistence: Events remain accessible for defined retention periods.
- Decoupling: Producers and consumers operate independently, enhancing flexibility for backend developers and full-stack teams.
Kafka Use Cases
Kafka finds extensive use across various industries, addressing diverse challenges with its ability to handle real-time data processing and scalable event streaming.:
- IoT: Process sensor data in real-time.
- Finance: Fraud detection and transaction monitoring.
- Healthcare: Process patient data streams.
- Retail: Real-time inventory tracking and recommendation systems.
- Gaming: Analyze player activity and engagement patterns.
Kafka in Action: Real-World Examples
- Netflix: Monitors events for real-time analytics.
- LinkedIn: Powers activity streams for its newsfeed.
- PayPal: Aggregates logs and tracks risks.
- Spotify: Delivers logs for analytics pipelines.
Kafka vs. RabbitMQ
While both Kafka and RabbitMQ facilitate messaging, they serve different needs:
- Kafka:
Best for event-driven architectures and systems requiring multiple consumers to process the same events.- Retains messages for configured durations.
- Consumers pull messages at their convenience.
- RabbitMQ: Ideal for traditional queue-based messaging.
- Deletes messages post-consumption.
- Pushes messages to consumers directly.
Pros and Cons of Kafka
Pros:
- Scales horizontally for massive data streams.
- Replicates data across brokers for fault tolerance.
- Supports real-time streaming with minimal latency.
- Decouples producers and consumers, enhancing system flexibility.
Cons:
- Complex to set up and requires expertise in cloud-native tools like Helm Charts.
- Memory-intensive and not suitable for lightweight messaging.
- Operational overhead due to tools like Zookeeper.
Conclusion
Kafka is a robust platform that plays a pivotal role in modern software development. Its scalability, real-time processing, and fault tolerance make it a preferred choice for backend developers and extended development teams. By understanding Kafka’s core concepts and use cases, developers can leverage it to build efficient and scalable systems.